
В 2015 году сервис Google Photos столкнулся с громким скандалом: встроенный в платформу определитель лиц на основе машинного обучения пометил фотографии двух чернокожих людей как «гориллы». Об этом пишет securitylab.ru.
Компания извинилась и пообещала исправить ошибку. Однако, как было быстро замечено пользователями, в качестве решения проблемы сервис просто перестал определять обезьян на фотографиях в принципе. И спустя восемь лет проблема так и не решена: Google Photos по-прежнему не может найти ни одного изображения обезьян в коллекции фотографий.
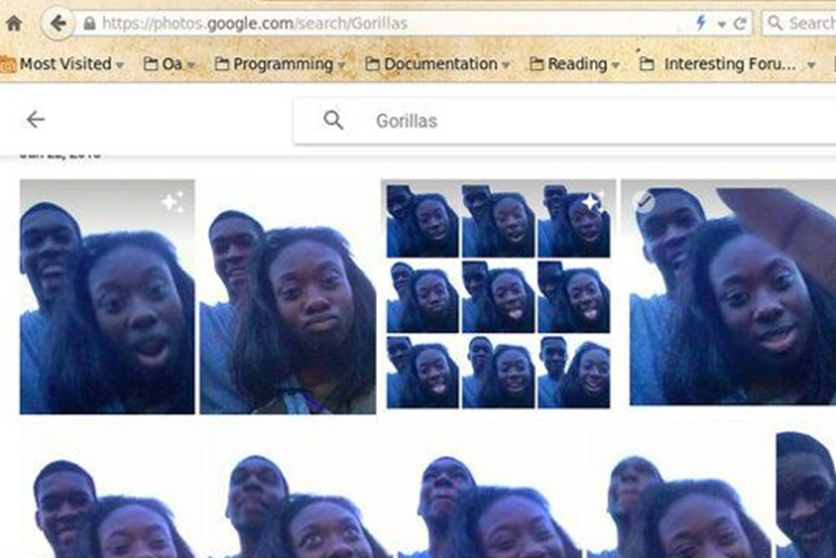
Скандальный пример тегирования из 2015 года
Исследователи издания The New York Times решили провести небольшой эксперимент и сравнить аналогичные приложения и сервисы по хранению и распознаванию фотографий от других технологических гигантов: Apple, Amazon и Microsoft. Они собрали 44 фотографии с людьми, животными и предметами и попробовали найти их по запросам.
Оказалось, что Apple Photos тоже не способен распознать большинство приматов. Приложение нашло фото гориллы только тогда, когда на нем был текст с этим словом. Microsoft OneDrive вообще не выдал никаких результатов по животным. Amazon Photos показал результаты по всем запросам, но они были слишком широкими: например, поиск по слову «горилла» выдал вообще всех обезьян. Когда как собак большинство сервисов способно определять с точностью до породы.
Единственное животное из семейства приматов, которое Google и Apple смогли определить, — это лемур. Вряд ли алгоритм вообще сможет спутать лемура с человеком из-за специфической расцветки шерсти и вечно удивлённого взгляда, потому, вероятно, он и определяется корректно.
Почему же так происходит? Возможно, Google и Apple боятся повторить ошибку 2015 года и именно поэтому насовсем отключили функцию распознавания обезьян. В случае с Google Photos два бывших сотрудника компании рассказали, что проблема была в том, что в коллекции изображений для обучения системы было недостаточно фотографий чернокожих людей. В связи с чем, итоговая система не была знакома с тёмным цветом кожи и спутала его с гориллами.
Это не единственный случай, когда технологии обвиняли в предвзятости. Ещё были примеры с веб-камерами HP, которые не могли обнаружить некоторых людей с темной кожей, и с Apple Watch, которые якобы не точно определяли уровень кислорода в крови у «цветных» людей.
Однако вряд ли стоит искать расисткие мотивы в любых неточностях работы подобных технологий. Уж с чем, а с подобными рисками не захочет сталкиваться ни одна технологическая компания. Поэтому специально «подшучивать» таким образом над представителями негроидной расы у компаний нет ни желания, ни возможности.
Так или иначе, искусственный интеллект и технологии машинного обучения с годами лишь совершенствуется, и возможно, ещё через несколько лет вышеупомянутые системы научатся определять любые объекты, животных и в том числе обезьян со стопроцентной вероятностью. Но пока существует погрешность, ни Google, ни Apple, ни кто-либо ещё — явно не хотят брать на себя ответственность за неидеальную работу своих систем, чтобы избежать репутационных рисков. И это на текущий момент — самое правильное решение.

