
Американские ученые из Массачусетского технологического института представили нейросеть Speech2Face, которая может воссоздавать по спектрограмме речи человека примерное изображение его лица.
Описание работы искусственного интеллекта опубликовано в arXiv.org.
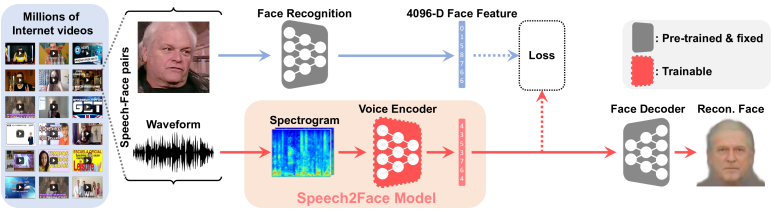
Нейросеть Speech2Face обучена на нескольких миллионах видео с голосом пользователей. Каждое видео разделено на дорожку аудио и видео.
Сам алгоритм разделен на несколько частей: одна из них использует все уникальные особенности лица из видеодорожки для создания снимка лица человека в анфас, другая пытается воссоздать из аудиодорожки ролика спектрограмму речи и смотрит, как выглядит анфас человека, который говорит на оригинальном видео.
В методологии нейросети изображение человека и голос делятся на три демографических показателя — пол, возраст и расу.
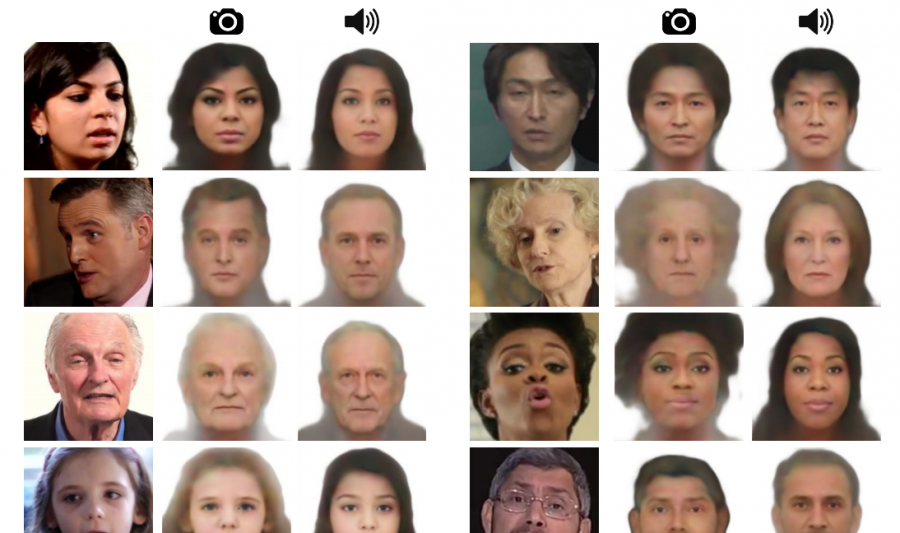
Во время тестирования ученым пока не до конца удалось научить нейросеть восстановить внешность человека на основе голоса.
Искусственный интеллект всегда может определить пол, а также чаще всего угадывает людей с азиатской и европеоидной внешностью. Однако пока Speech2Face не может точно определить возраст даже с разницей в десять лет.
Ученые отметили, что главное в работе Speech2Face — все же не создание точной копии изображения человека по его голосу, а выделение из него некоторых точных параметров. При этом, естественно, по голосу человека невозможно понять, какой у него формы нос или находится ли на лице объекта крупная родинка.
